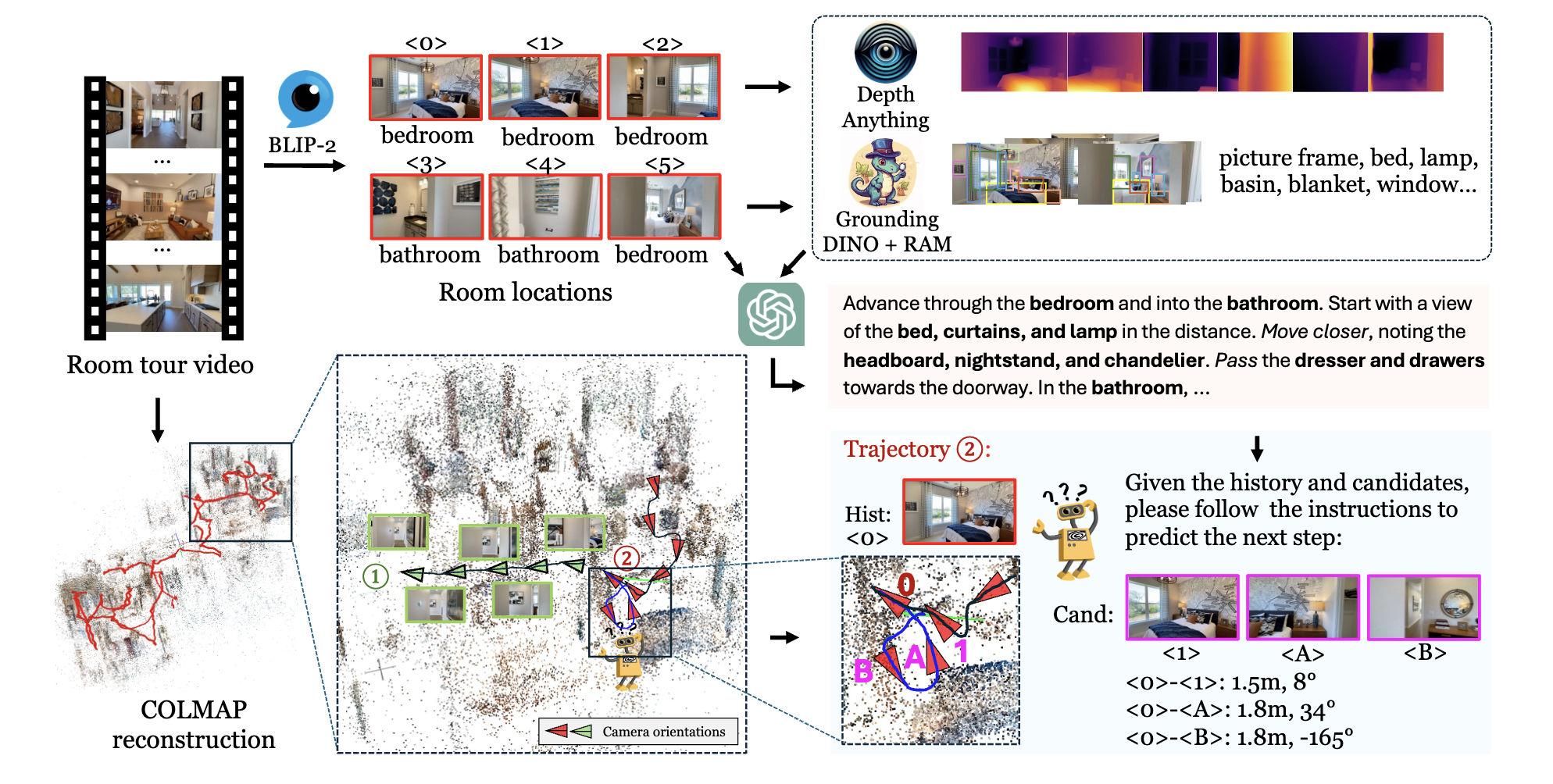
Vision-and-Language Navigation (VLN) suffers from the limited diversity and scale of training data, primarily constrained by the manual curation of existing simulators. To address this, we introduce RoomTour3D, a video-instruction dataset derived from web-based room tour videos that capture real-world indoor spaces and human walking demonstrations.
Unlike existing VLN datasets, RoomTour3D leverages the scale and diversity of online videos to generate open-ended human walking trajectories and open-world navigable instructions. To compensate for the lack of navigation data in online videos, we perform 3D reconstruction and obtain 3D trajectories of walking paths augmented with additional information on the room types, object locations and 3D shape of surrounding scenes.
Our dataset includes ~100K open-ended description-enriched trajectories with ~200K instructions, and 17K action-enriched trajectories from 1847 room tour environments. We demonstrate experimentally that RoomTour3D enables significant improvements across multiple VLN tasks including CVDN, SOON, R2R, and REVERIE. Moreover, RoomTour3D facilitates the development of trainable zero-shot VLN agents, showcasing the potential and challenges of advancing towards open-world navigation.
@article{han2024roomtour3d,
title={RoomTour3D: Geometry-Aware Video-Instruction Tuning for Embodied Navigation},
author={Mingfei Han and Liang Ma and Kamila Zhumakhanova and Ekaterina Radionova and Jingyi Zhang and Xiaojun Chang and Xiaodan Liang and Ivan Laptev},
journal={arXiv preprint arXiv:2412.08591},
year={2023}
}